
在上一篇arduino学习之—led灯控制中,我们做了用输出口高低电瓶控制led闪烁的尝试,并使用pc发送指令的方法控制led的熄灭。
在上一篇arduino学习之—led灯控制中,我们做了用输出口高低电瓶控制led闪烁的尝试,并使用pc发送指令的方法控制led的熄灭。
大多数架构师在回顾重构过程的时候都会感慨:“要是早点重构就不会这么麻烦了”,不过在下一次重构到来之前,永远没人知道“早点”究竟是何时,同样的感慨会反复被提起。那到底有什么办法找到最合适的重构时机?本文作者杜欢是滴滴平台产品中心技术总监,他就这个问题进行了探讨,不一定能找到最终答案,或者这个问题本身就没有答案,但希望能给读者一些思路,如果你有想法,别忘了评论。
微服务是一种新的架构,它使用简单、轻量、松耦合的服务来构建系统,这些服务彼此可以独立开发和发布。

这里使用arduino UNO r3板子+7个电阻+7个led来学习如何实现定时闪烁和顺序亮起。

作为一种基础的抽象数据结构,队列被广泛应用在各类编程中。大数据时代对跨进程、跨机器的通讯提出了更高的要求,和以往相比,分布式队列编程的运用几乎已无处不在。但是,这种常见的基础性的事物往往容易被忽视,使用者往往会忽视两点:
当你登录到一台存在性能问题的Linux服务器上时,在头一分钟,你会检查什么?
《社交网络》里,讲述了脸书曲折的创业史以及官司纠纷。
我们在做类似搜索相关的特定服务时,通常都会遇到分词解析query,取出其中特定关键字进行检索的问题,这里提供一个简单的基于词槽的query匹配方法。
架构师,当然是脑力劳动者,但是,同样是脑力劳动也存在重大的差别。有一类脑力劳动的成果,是比较容易被评价的。或者能够判断其对错:比如考试的分数;或者能够比较其高下:比如两个人下棋分出输赢;或者能够交由市场来判断:比如某种UI/UE设计,我们可以通过数据统计,了解其受用户欢迎的程度。

CAP理论,被戏称为[帽子理论]。CAP理论由Eric Brewer在ACM研讨会上提出,而后CAP被奉为分布式领域的重要理论【link1】 。
在影响团队长远战斗力的诸多因素中,比较有意思同时也非常关键的一个因素是对tech lead 的选择和培养,这也是我们今天的话题。
消息队列已经逐渐成为企业IT系统内部通信的核心手段。它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。 当今市面上有很多主流的消息中间件,如老牌的ActiveMQ、RabbitMQ,炙手可热的Kafka,阿里巴巴自主开发的Notify、MetaQ、RocketMQ等。 本文不会一一介绍这些消息队列的所有特性,而是探讨一下自主开发设计一个消息队列时,你需要思考和设计的重要方面。过程中我们会参考这些成熟消息队列的很多重要思想。 本文首先会阐述什么时候你需要一个消息队列,然后以Push模型为主,从零开始分析设计一个消息队列时需要考虑到的问题,如RPC、高可用、顺序和重复消息、可靠投递、消费关系解析等。 也会分析以Kafka为代表的pull模型所具备的优点。最后是一些高级主题,如用批量/异步提高性能、pull模型的系统设计理念、存储子系统的设计、流量控制的设计、公平调度的实现等。
sort 命令可以按照字母或者数字顺序排列字符串,不过如果我们想根据字符串的长度来排序呢?
介绍两个常用命令:
给娃讲历史用...
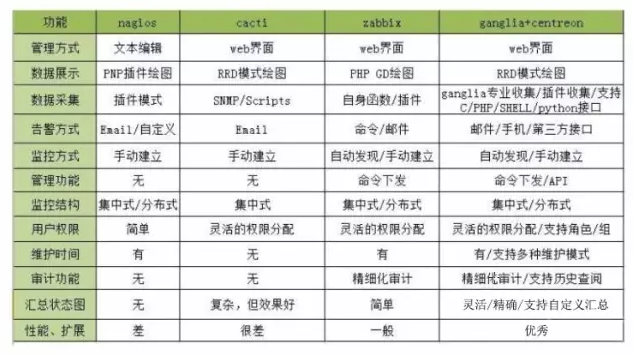
Cacti是一套基于PHP,MySQL,SNMP及RRDTool开发的网络流量监测图形分析工具。
大家普遍认为,buffers和cached所占用的内存空间是可以在内存压力较大的时候被释放当做空闲空间用的。但真的是这样么?在论证这个题目之前,我们先简要介绍一下buffers和cached是什么意思
2. 对象存储,典型的就是Amazon S3,这种系统很多公司自己造给公司内部用,存图片等小文件,接口一般不会兼容Amazon S3,因为不需要,比如淘宝的TFS,基本思路就是将多个小文件合并成大文件存储,经典论文FB的HayStack。这种系统一般读多写少,不需要修改,很少删除,一致性也没那么强,系统相对好做。基本上HDFS+HBase就能搞定一个这种系统,HBase存元数据,利用HDFS的Append功能将小文件合并成大文件。
昨天做了个摇号分享抽奖小活动,加了几道反作弊功能,其中第一道是通过IP进行过滤,通过对数据进行监控,发现有大量3G/4G用户的IP是相同的,估计是各移动运营商用户量暴增,公网IP有限。

以前,我们邀请几位嘉宾讨论了他们在开发微服务时遇到的挑战,比如Fred George或Dustin Huptas和Andreas Schmidt。近日,Usman Ismail参加了一场小组会议,讨论了微服务持续交付面临的挑战,并决定随后详述其中的部分重点内容。他首先讨论了微服务其中一个基本原则的缺点,即允许大型团队通过快速原型和迭代以一种更加敏捷的方式推进(软件)开发: