go的import与python或java不太一样,第一次搞go开发在本地封装lib后import时可能会浪费不少时间,这里说明下,go的import分两种场景:
go如何import本地包
发表评论
go的import与python或java不太一样,第一次搞go开发在本地封装lib后import时可能会浪费不少时间,这里说明下,go的import分两种场景:
问题:
当我们使用 go get、go install、go mod 等命令时,会自动下载相应的包或依赖包。但由于众所周知的原因,类似于 golang.org/x/… 的包会出现下载失败的情况。如下所示:
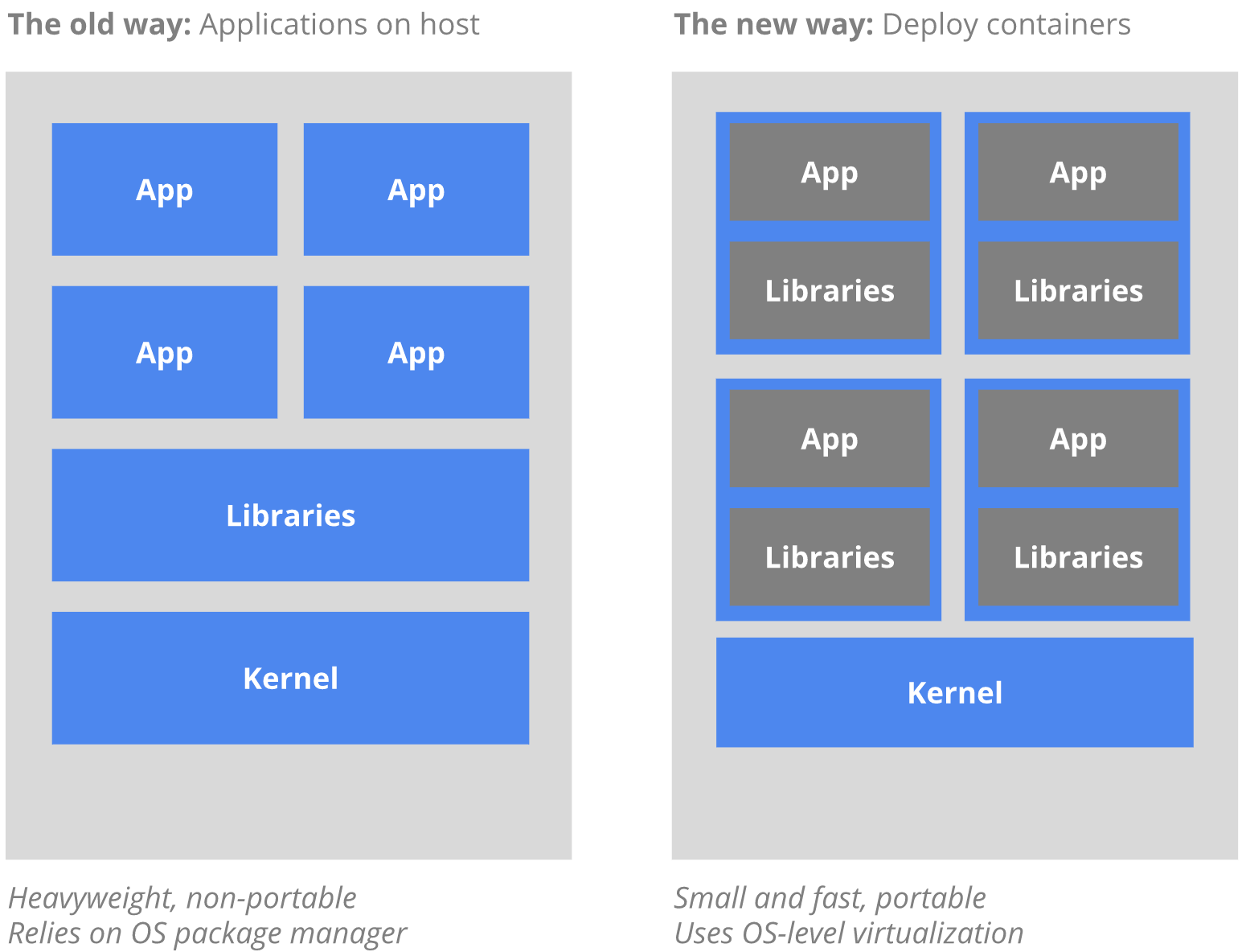
Kubernetes是容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
本文用实例演示如何把自己的python代码库打包上传pypi,以使用pip进行安装。
简单点说,这个工具能解决nohup python faceswap.py train & 报cannot connect to X server的问题,即远端的程序不能后台运行,但是你的网络又经常会断开,用Tmux就好了
一个非常方便的视频<->图片互转工具:视频截帧、帧图片合成视频、添加水印/字幕等。
使用c++开发程序时,经常会遇到运行中core的情况,如果是偶发的就更加难以定位,本文讲解如何使用gdb进行core位置的分析定位。
jupyter notebook里的代码有py2.7也有py3.0的,本文讲解如何使jupyter同时支持多个python版本(python2.7.5 + python3.6.2)。
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
skimage即是Scikit-Image。基于python脚本语言开发的数字图片处理包,比如PIL,Pillow, opencv, scikit-image等。 PIL和Pillow只提供最基础的数字图像处理,功能有限;opencv实际上是一个c++库,只是提供了python接口,更新速度非常慢。scikit-image是基于scipy的一款图像处理包,它将图片作为numpy数组进行处理,与matlab一样。
LSM树整个结构不是有序的,所以不知道数据在什么地方,需要从每个小的有序结构中做二分查询,找到了就返回,找不到就继续找下一个有序结构。所以说LSM牺牲了读性能。但是LSM之所以能够作为大规模数据存储系统在于读性能可以通过其他方式来提高,比如读取性能更多的依赖于内存/缓存命中率而不是磁盘读取。
概述:https://blog.csdn.net/D_Guco/article/details/80641236
MySQL vs RocksDB vs TiDB 完全版性能测试:http://liky.farbox.com/post/tidb
三大主流软件负载均衡器对比(LVS vs Nginx vs Haproxy)
最近做点小程序,服务端api必须是https域名,配置方法如下:
自己生成CA证书:(自己生成的根证书浏览器不认,会提示不安全,但https可访问)
cd /home/openssl
openssl genrsa -des3 -passout pass:123456 -out test.pem 2048 #生成RSA私钥
openssl rsa -passin pass:123456 -in test.pem -out test.key #提取密钥中的公钥
openssl req -new -key test.key -out test.csr -subj /C=CN/ST=beijing/L=beijing/O=YAN/CN=www.yanjingang.com #生成证书请求文件
openssl x509 -req -days 365 -in test.csr -signkey test.key -out test.crt #生成自签名证书
openssl x509 -in test.crt -noout -text #查看证书文件阿里云、百度云有免费的单域名DV证书(下载注意选择nginx版本证书)
PHP7已经发布, 如承诺, 我也要开始这个系列的文章的编写, 主要想通过文章让大家理解到PHP7的巨大性能提升背后到底我们做了什么, 今天我想先和大家聊聊zval的变化.

程序概念、int变量、if判断、函数概念
#include <stdio.h>
int main()
{
/* YJY */
int num = 1;
printf("%d\n", num);
if(num == 1){
printf("YJY\n");
}else{
printf("YAN\n");
}
/* jiafa lianxi */
int num1 = 89;
int num2 = 107689;
int result = sum(num1, num2);
printf("%d\n", result);
return 0;
}
/* sum */
int sum(int num1, int num2){
return num1+num2;
}
2018.10.20
| 用途 | 推荐使用的安全的密码算法 | 常见的不安全的密码算法 |
| 对称加密 | AES(密钥长度>=128bits) | DES、3DES、RC2、RC4 |
| 哈希算法 | SHA256或以上 | MD5、SHA1 |
| 非对称加密 | RSA(密钥长度>=2048bits) | RSA(密钥长度<=1024bits) |
| 数字签名 | RSA(密钥长度>=2048bits) | RSA(密钥长度<=1024bits) |
| 密钥交换 | DH(密钥长度>=2048bits) | DH(密钥长度<=1024bits) |
备注:
1. AES不建议使用ECB(同样的明文总是会产生相同的密文),推荐使用CBC模式。
2. 应注意编码及加密的区别,例如base64属于编码而不属于加密。
3. 加解密中建议使用安全随机数,如java.security.SecureRandom,类Unix系统 (包括OS X): /dev/random;不安全随机数如C标准函数random(),java.util.Random()。
4. 不建议使用私有、非标准化的加解密方式。
上次我们进行了简单的环境安装和模型应用尝试,今天开始通过paddlepaddle的房价预测看一下简单的线性回归有监督模型是怎么训练出来的。